서비스가 커지고 문제가 복잡해질수록, 이를 처리하기 위한 소프트웨어의 아키텍쳐적인 부분이 중요해진다.
내가 진행했던 토이프로젝트의 서버는 크게 세 가지 일을 했다.
-새로운 데이터를 처리
-서비스로직을 처리(시간표그려주기 등)
-기존의 데이터를 이용 (db 활용)
Spring 에서는 해당 부분들이 각각의 레이어로 나누어져있다.
-Presentation layer : 사용자와 상호작용하는 처리 계층. CLI, HTTP요청, HTML처리 등을 담당 (Model, View, Controller..)
==> 특정 url에 요청을 보내면 해당 url에 묶인 메서드가 호출되었던 부분과 비슷.
Spring에서 @Controller로 표현
-Domain(business / service) layer : 서비스나 시스템의 핵심 로직. 유효성 검사, 계산 등 어플리케이션의 도메인과 관련된 작업들을 담당함. 프로그램이 복잡해지면, 비지니스 로직을 수행하기 위한 별도의 계층이 필요하다. 그게 Domain layer
Spring에서 @Service로 표현
-Data Access(persistence) Layer (DAO 계층) : Database / Message Queue / 외부 API와의 통신 등을 처리한다.
DB 혹은 데이터 소스가 서버 외부에 별개로 존재하는 경우가 매우 많기 때문에, 데이터 소스와의 소통계층이 필요함.
Spring에서 @Repository로 표현
레스토랑에 비유하면
@Controller : 웨이터
@Service : 쉐프
@Repository : 주방보조 (재료가져다줌)
<Database>
DBMS : Database Management System
RDBMS : Relational Database Magagement System
==RDBMS==============
-테이블이라는 최소 단위로 구성되고, 테이블은 열과 행으로 이루어져있다.
-MySQL, PostgreSQL, Oracle 등
======================
H2 : In-memory DB의 대표주자. 인메모리DB란 서버가 작동하는 동안에만 내용을 저장하고, 서버를 닫으면 데이터가 모두 삭제 ==> 연습용으로 좋다.
<SQL> : Structured Query Language : RDBMS에서 사용하는 언어
=====DDL===== : Data Definition Language : 테이블이나 관계의 구조를 생성하는데 사용
CREATE DATABASE 데이터베이스이름;
CREATE TABLE 테이블이름
(
필드이름1 필드타입1,
필드이름2 필드타입2,
...
)
ALTER TABLE 테이블이름 ADD 필드이름 필드타입;
ALTER TABLE 테이블이름 DROP 필드이름;
ALTER TABLE 테이블이름 MODIFY COLUMN 필드이름 필드타입;
DROP DATABASE 데이터베이스이름;
DROP TABLE 테이블이름;
TRUNCATE DATABASE 데이터베이스이름;
TRUNCATE TABLE 테이블이름;
=====DCL===== : Data Control Language : 데이터의 사용 권한을 관리하는데 사용
GRANT SELECT , INSERT : 권한 부여
ON mp
TO scott WITH GRANT OPTION;
REVOKE SELECT, INSERT : 권한 회수
ON emp
FROM scott
[CASCASE CONSTRAINTS];
=====DML===== : Data Manipulation Language : 테이블에서 데이터를 검색 / 삽입 / 수정 / 삭제
INSERT INTO 테이블이름 (필드이름1,필드이름2,필드이름3...) VALUES(데이터값1, 데이터2, 데이터3....)
INSERT INTO 테이블이름 VALUES (데이터1,데이터2,데이터3....)
SELECT 필드이름 FROM 테이블이름 WHERE[조건];
UPDATE 테이블이름 SET 필드이름1 = 데이터값1, 필드이름2 = 데이터값2...... , WHERE 필드이름 = 데이터값;
DELETE FROM 테이블이름 WHERE 필드이름 = 데이터값;
<SQL Cheatsheet>
=====CREATE 제약조건들=====
AUTO_INCREMENT : 컬럼의 값이 중복되지 않게 1씩 자동으로 증가하게 해줘 고유번호를 생성
NOT NULL : 해당필드는 NULL값을 저장할 수 없게됨
UNIQUE : 해당필드는 서로 다른값을 가져야만 함
PRIMARY KEY : 해당필드가 NOT NULL과 UNIQUE 특징을 모두 가지게 됨
==> 테이블에 유일하게 존재하는 값의 조합을 설정해서 중복된 데이터가 테이블에 삽입되는 것을 방지하는 제약조건
==> 데이터의 무결성을 위해서 사용, 데이터를 빠르게 검색할 수 있게 됨
FOREIGN KEY : 두개의 테이블을 연결하는 다리 역할을 하는 KEY
==> FOREIGN KEY (필드이름) REFERENCES 테이블이름(필드이름)
==> FOREIGN KEY 역시 데이터의 무결성을 보장. FK를 적용하려는 컬럼이 참조하는 테이블의 컬럼은 PK, UNIQUE
어플리케이션이 데이터베이스를 직접 다룰 때의 문제점
- 훨씬 번거롭다 : 테이블 만들고, 쿼리 작성하고, 쿼리를 jdbc api통해 실행, 결과 객체도 직접 만들어줘야함
- SQL의존적이다: SQL에 컬럼을 추가하면, 관련된 객체, 쿼리문 등등 모든 부분을 수정해야함 => 비지니스로직보다 SQL↑
- 패러다임 불일치
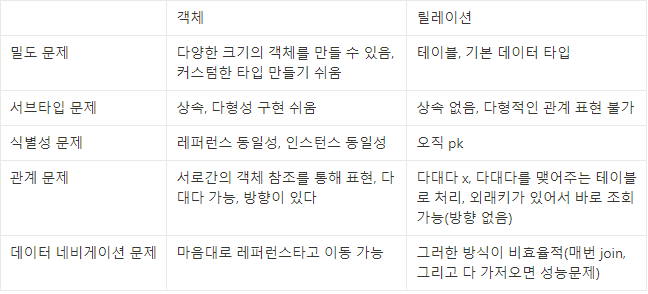
==> ORM, JPA 기술의 등장
ORM : object relation Mapping
<JPA> : Java Persistence API
=>자바 ORM 기술에 대한 표준 명세
1. 쿼리를 자동으로 만들어줌
2. 어플리케이션 계층에서 sql 의존성을 줄임 (번거로운 반복작업 ↓)
3. 패러다임의 불일치 해결
4. 방언을 지원하기 때문에, h2 DB, mySQL, oracle 등 SQL표준을 준수한 DB무엇을 붙여도 같은 코드로 쓸 수 있다.
@Entity annotation을 통해 해당 클래스가 DB의 테이블 역할을 한다는 것을 알려준다.
@OneToMany // @ManyToOne // @OneToOne // @ManyToMany : Entity들의 연관관계 형성
eg) Food 엔티티의 food // Orders 엔티티의 food_id가 매핑되어야 한다고 할 때,
Food 클래스 안에서:
@OneToMany(mappedBy = "food", fetch = FetchType.EAGER)
private List<Orders> orders = new ArrayList<>();
Orders 클래스 안에서:
@ManyToOne
@JoinColumn(name = "food")
private Food food; ==> 생성자까지 추가해줘야함
repository 패키지에 각 entity별로 FoodRepository와 같이 생성
public interface FoodRepository extends JpaRepository<Food, Long>{}
foodRepository.saveAll(List<Food>)와 같이 사용 가능
메서드들 : save, saveAll, findAll, findById 등등
웬만한 기능들은 JpaRepository에 구현 되어있기 때문에, Repository 구현체에서 override 해주면 된다.
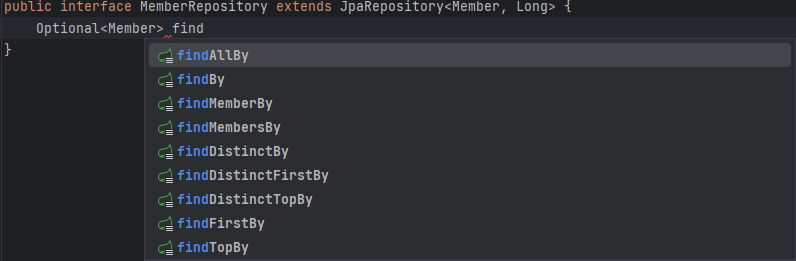
https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#jpa.query-methods 에서 query method 들을 확인가능
<추가 공부>
-영속성 컨텍스트, 1차 캐시
'공부 > Spring' 카테고리의 다른 글
| ExceptionHandler // ResponseEntity // HTTP 상태 반환 (0) | 2023.04.23 |
|---|---|
| 간단한 게시판 CRUD // 로그인, 회원가입, JWT 추가 (0) | 2023.04.20 |
| Auth // JWT (0) | 2023.04.19 |
| Spring Boot 간단한 게시판 만들어보기 // POSTMAN (0) | 2023.04.18 |
| Spring MVC 패턴 이해하기 (0) | 2023.04.16 |








