connection 요청마다 프로세스 생성 -> (C10K problem) : 요청이 많아져 connection이 많아지면 메모리 부족, CPU 부하 증가(context switching) // but 모듈구성으로 확장성 good
NGINX : async, event-driven approach. master process가 생성한 worker process들이 작업큐에 있는 작업을 처리하는 구조로, 요청마다 프로세스를 생성하지 않기 때문에 요청당 메모리 사용량 ↓, context switching 비용 ↓. (worker는 일반적으로 core 개수만큼 생성) -> C10K problem 해결, 고성능 // but 설정이 비교적 자유롭지 x
웹서버를 단독으로 쓸때는 정적인 컨텐츠를 서빙하지만, 동적인 컨텐츠가 필요할 경우 WAS에 요청을 전달하여 여 처리(프록시 기능)
<WAS>
- DB 조회나 비지니스 로직 처리 등 동적인 컨텐츠에 대한 요청을 처리
Tomcat : Web server + Servlet 구동환경을 제공하고, Servlet의 생명주기를 관리하여 Servlet Container라고도 불림
Servlet : Java Enterprise Edition의 일부로서, HTTP 요청(GET, POST 등)을 받아 처리하고 HTTP 응답을 반환함.
Spring을 통해 작성한 소스코드 -> 컴파일 -> Servlet Container (Tomcat) 등록 -> HTTP 요청 올 시 Servlet Container(Tomcat) 이 Servlet을 찾고, 쓰레드풀에서 쓰레드를 가져와 처리
https://velog.io/@jakeseo_me
웹 서버와 WAS를 따로 두는 이유 : Application Server가 비지니스 로직에 더 집중할 수 있도록 하기 위함, 부하를 분산
채팅 기능의 logic은 테스트 해보았고, 우리 팀원들과 함께 테스트했을 때는 만족스러운 결과가 나왔다.
현재는 채팅 서버가 따로 분리되어있지도 않고, ec2 사양도 프리티어로 돌고있다.
현재 상황에서 얼마나 많은 채팅 connection을 버틸 수 있는지 확인해보려고 한다.
테스트는 JMeter를 활용해서 진행하려고 한다. JMeter를 활용하여 웹소켓을 테스트하려면
JMeter 설치 -> plugins manager 설치 -> websocket sampler 설치 해야한다.
자료가 많아 참고하여 설치하였다.
1. 로컬 환경에서 JMeter 연습해보기
테스트 생성 -> 쓰레드그룹 생성 -> 쓰레드 수 설정 -> 설정과 sampler들 등록
sampler 조합
대략 이런식으로 설정하였다.
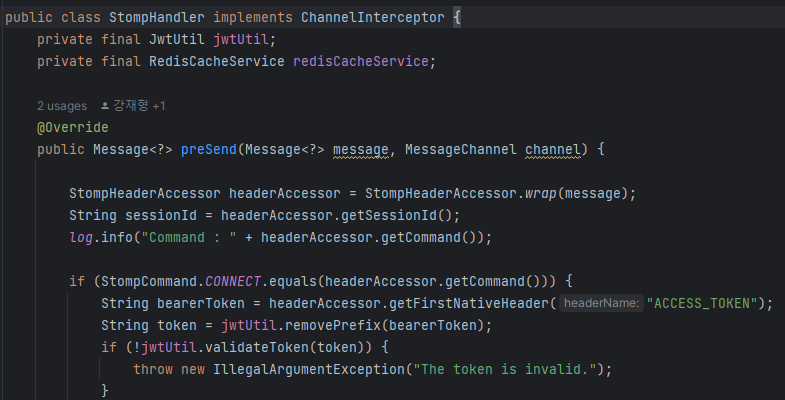
프론트에서 SockJS로 웹소켓 연결을 한다고 하는데, 이 경우 SockJS 연결시에는 헤더를 보낼 수 없기 때문에 SockJS 연결 직후에 오는 STOMP CONNECT 메시지 헤더에 JWT 토큰을 담아주게 된다. 따라서, 이 상황을 구현하려면 STOMP 메시지 프로토콜에 대한 기본적인 이해가 필요했다.
CONNECT 요청데이터
이와같이 클라이언트에서 보내는 STOMP 메시지의 형식을 갖추어야한다.
SUBSCRIBE, SEND 요청데이터
또한, CONNECT와 Websocket 커넥션같이 응답이 오는 경우에는 그 뒤에 websocket read sampler를 달아주어야 응답 latency를 알 수 있으며, DISCONNECT시 밀려있던 다른 프레임의 메시지를 받아 오류가 나는 경우를 방지할 수 있다.
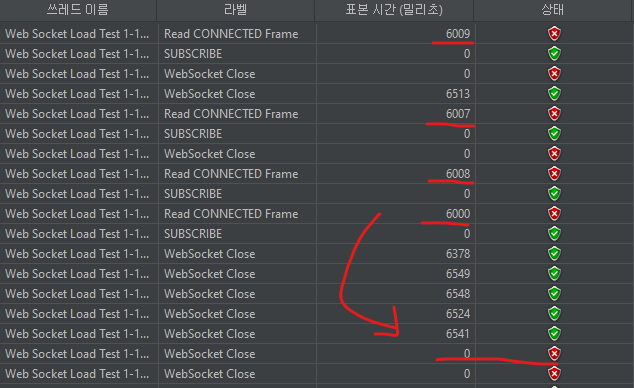
채팅서비스 네트워크탭에서 확인할ㄴ 수 있다.요약보고서 탭 - 100개의 connection을 10초동안 받은 결과
websocket connection은 평균 8ms, STOMP connection은 평균 13ms가 나왔다.
요약보고서 탭 - 1000개의 connection을 10초동안 받은 결과
1000명의 사용자가 connect / subscribe / disconnect 하는 경우, 에러없이 처리가 되긴 하지만 평균 latency가 어느정도 늘어난 것을 확인할 수 있다. 현재는 연습을 위해 일부 로직(사용자가 입장 시 lastMessageId를 클라이언트에 전달하는부분)을 주석처리 해둔 상태임에도 처리시간이 늘어나고 있다.
요약보고서 탭 - 1500개의 connection을 10초동안 받은 결과요약보고서 탭 - 2000개의 connection을 10초동안 받은 결과
에러가 나기 시작했다.
확인결과, STOMP CONNECT 요청 후에 응답으로 CONNECTED 프레임을 받는 것이 timeout나면서 버퍼에 쌓여 close시에 DISCONNECT 프레임이 아닌 CONNECTED 프레임을 받아 에러가 나는 것이었다.
2.Baseline 설정 / 서버 테스트
위에서 설정한 쓰레드 수가 1000이라고 해서 서버가 1000개의 socket connection을 동시에 유지한다고 보기는 어렵다. ramp-up 시간동안 쓰레드가 생성될 때, 기존에 생성된 쓰레드는 disconnect 요청을 마치고 connection을 반환했을 것이기 때문이다. 따라서, ramp-up period는 길게 유지하되 subscribe 이후에 send 요청에 루프를 걸고, think-time을 주어서 유저가 10초에 한번씩 지속적으로 채팅을 전송하는 상황을 재현하였다. 루프는 6 이상을 주어 하나의 스레드가 ramp-up time보다 길게 연결을 지속하게 하였다.
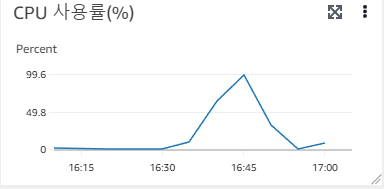
그냥 CPU 문제였다.. 병목이고 나발이고 EC2 프리티어는 이렇게 빠르게 들어오는 요청을 감당할 수 없었던 것이다.
요청이 너무 빠르게 들어오면 못버티는 것 같다. 현재는 짧은 시간 안에 많은 connection을 만드는 것 보다,
최대 몇 개의 connection을 유지하고 채팅기능이 작동하는지가 관심사기 때문에 ramp-up 시간을 늘리고 쓰레드수를 줄여보았다.
thread 300 / ramp-up 60thread 400
마찬가지로 정확히 thread 수가 370을 넘어가면서 connection 에러가 나기 시작했다.
이번엔 CPU가 튄것도 아니고, 메모리 부족도 아닌데 이유가 궁금했다.
여기저기서 주워들은 것들로 3가지 가설을 세웠다.
1. chat을 publish하기 전에 db에 저장하는 부분에서 병목이 생기고, 이로인한 connection timeout
==> db 혹은 redis가 병목이었으면 로컬에서도 마찬가지였어야함
2. connect, subscribe, send, unsubscribe 모두 redis를 사용하기 때문에 redis에서의 병목
==> db 혹은 redis가 병목이었으면 로컬에서도 마찬가지였어야함
3. 우분투 file descriptor 제한 문제(이건 지금 당장은 아닌 것 같다)
==> 로컬과 서버의 ulimit file open 설정이 1024로 동일하고, 이 설정을 올렸을 때도 서버 테스트 결과가 같았다.
4. tomcat의 connection 제한이나 jvm 메모리 문제
이것들을 모두 검증해보기엔 내가 사용할줄 아는 모니터링 툴이 제한적이고, 탐색범위가 너무 넓기 때문에 일단은 지금 서버가 감당할 수 있는 채팅 유저를 300으로 생각하고 테스트를 마무리 하려고 한다. 먼저 redis에 호출이 과하게 많은 부분을 개선하고, 외부 message broker를 사용해 채팅 서버를 분산해본 뒤 다시 한번 테스트 해봐야겠다.
3.결론 & 느낀점
결론적으로 현재 moyiza 서비스의 ec2 서버는 약 300명정도가 채팅서버에 연결되어 채팅을 주고받을수 있는 상황이다.
경험이 없어 ec2 프리티어 스펙에 어느정도를 목표로 잡아야할지 모르는 것이 너무 안타깝다. 로컬과 ec2 차이가 cpu, 메모리밖에 없는데 도대체 왜 ec2 CPU와 메모리가 놀고있는 상황에도 차이가 나는지 알 수가 없다.
느낀점
1. 아무것도 모르는 상태에서 테스트하는 것이 정말 쉽지 않다. Jmeter 사용법 알아내서 익히면 websocket 테스트하는법 배워야하고, connection 이후에 구독, 전송 등 STOMP 프로토콜에 specific하게 테스트 시나리오 작성해야하고, 새로운 것을 사용하는건 항상 어려운 일인 것 같다.
2. 적절한 모니터링 툴을 잘 사용하는 것이 중요하다. 테스트 시나리오를 짜서 테스트를 했는데, 막상 일정 load 수치에서 장애가 나도 어느 부분을 개선해야할지 막막하다. 알아야할 것이 굉장히 많고, 어디를 봐야할지 몰라서 이것저것 툴을 설치해도 정확하게 파악하기가 어렵다.
WebSocket Connection은 잘 맺어지는데 STOMP Connection이 먼저 망가지는 것을 보고 자바 어플리케이션에 할당된 메모리가 차서 그런 것인가 싶어 -Xmx 옵션을 통해 로컬에서 실행하는 어플리케이션의 최대 힙 메모리를 제한하고 실행해도 결과는 바뀌지 않았다.. 로컬에서 바라보는 redis와 db를 개발서버와 동일하게 맞춰주어도 로컬은 문제 없는 것을 보면 저장소 쪽의 병목은 아닌 것 같은데 도저히 이유를 모르겠다. 문제 상황이 재현이 안되니까 너무 슬프다....
삽질한 김에 명령어 정리 : java 실행 명령어 -Xmx512m ==> JVM 최대 힙 메모리 설정, -Xms는 최소
기본적인 Pub/Sub 채팅 서버 구현이 완료된 이후, 추가기능으로 카카오톡처럼 안읽은사람의 count를 구현해보기로 결정했다. 해당 기능 구
현에 필요함에 더해, 몇 가지 이유로 redis를 사용하기로 결정했다. 이 글에서 관련한 내용을 정리하려고 한다.
1. Redis 도입
- 최근 채팅 저장 용도 : 우리 서비스는 채팅 기록을 하나의 Mysql 테이블에 쌓고 있다. 따라서 채팅방 A,B,C,D에서 채팅이 활발할 경우, DB 삽입이 자주 일어나 다른 채팅방에 입장한 사람이 채팅방의 최근 채팅 목록을 조회하는 것이 느려질 수 있다고 생각했다. redis 역시 싱글스레드이므로 많은 쓰기 요청이 있을 경우 해당 요청들에 의해 block이 있긴 하겠지만, 디스크I/O보다 빠를 것이고, 채팅방 별 최근 채팅내역을 저장하는 상황에서는 조회도 훨씬 빠를 것이기에 성능상의 이점이 있을 것이라고 생각했다.(성능을 비교하여 검증하진 못함. 다만, 다른 조에서 구현했던 채팅 서버에 도배가 일어났을 때 채팅 로드 속도가 많이 저하됐던 것을 기억하여 이렇게 판단)
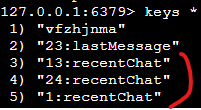
==> {chatId}:recentChat key에 chatMessageOutput object를 50개의 limit을 가지는 List로 저장하기로 결정
redis keys
- WebSocket Disconnect handling 용도 : 아래 작성할 안읽은 유저 count 구현 로직에서, 특정 유저가 채팅방의 구독을 끊었을 때, 채팅방의 마지막 메시지(유저가 읽은 마지막 메시지)를 저장하게 되었다. 유저가 얌전하게 채팅방의 구독을 종료해준다는 가정이 있다면 프론트에서 해당 시점에 chatId와 유저정보를 넘겨주면 되겠지만, 대부분의 경우는 구독이 되어있는 상황에서 브라우저를 닫아 websocket connection이 종료되는 상황일 것이다. websocket connection이 끊어지는 경우에 서버에서 알 수 있는 것은 DISCONNECT로 오는 stomp message 헤더에 있는 sessionId 뿐이다. 따라서, 이런 경우 구독되어있는 목록을 확인하고 UNSUBSCRIBE를 핸들링 해주기 위해 세션정보와 구독정보 등을 담을 저장소가 필요했고, 이에 적절한 것이 redis라고 판단했다.
==> 이전 글에서 사용한 JWT 인증방식을 이제 CONNECT 요청에서만 검증하고, 해당 유저 정보와 sessionId를 묶어 redis에 저장한다.
redis template
추가로 채팅 안읽음 count 구현에 필요한 몇 가지를 redis에 저장한다.
2. 채팅 안읽은 숫자 구현
고민해야 할 부분은 다음과 같다.
(1) U 유저가 A 채팅방에 오래간만에 들어갔을 경우, A 채팅방을 보고 있는 사람들에게 U 유저가 읽은 메시지들의 숫자가 감소되어야 함
(2) 모든 채팅 기록들의 readCount를 나중에도 알 수 있어야함
(3) 채팅방 구성원의 변동에 대응할 수 있어야함
■구현 방법 구상
(1)과 관련하여, 무조건 유저가 해당 채팅방에 마지막으로 어떤 메시지를 읽었는지는 알아야함
(1-1) 중간테이블을 만들어 chatId, userId, lastMessageId를 기록
-> A 유저가 채팅창을 보고 있는 경우 메시지 하나마다 읽었다는 기록이 서버로 오고, 테이블을 update 해주어야함
(1-2) chatJoinEntry 테이블에 lastMessageId 컬럼을 추가
->DB 구성이 이상해지는 것 같고, 1-1과 동일한 문제 발생
==>공통적으로 lastMessage를 너무 자주 업데이트 해주어야 한다는 문제가 있다.
(2)와 관련하여 메시지별 readCount를 저장하거나, 시점에 관계없이 계산할 수 있는 로직이 필요
(2-1) 메시지 record 별 readCount 컬럼을 가지게 한다.
-> 메시지 안읽은 메시지가 1000개인 사람이 채팅방에 들어오면 1000개의 row를 테이블에서 업데이트 해줘야함
(2-2) A메시지의 readCount는 해당 채팅방에서 lastMessageId가 A메시지의 id보다 큰 사람일 것이므로, lastMessage를 통해 readCount를 계산하는 방법
-> 조금 더 그럴듯해 보인다. 하지만, (1-1)의 문제와 마찬가지로 메시지가 하나 전송될 때마다 n명의 lastMessage를 모두 업데이트 해줘야하는 문제점이 동일하게 있음
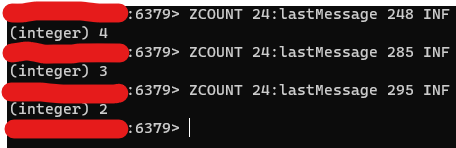
Redis의 sorted set 자료구조를 사용하여 ZCOUNT(messageId, inf)를 구하면 inactive user들의 readcount를 구할 수 있다.
■구현
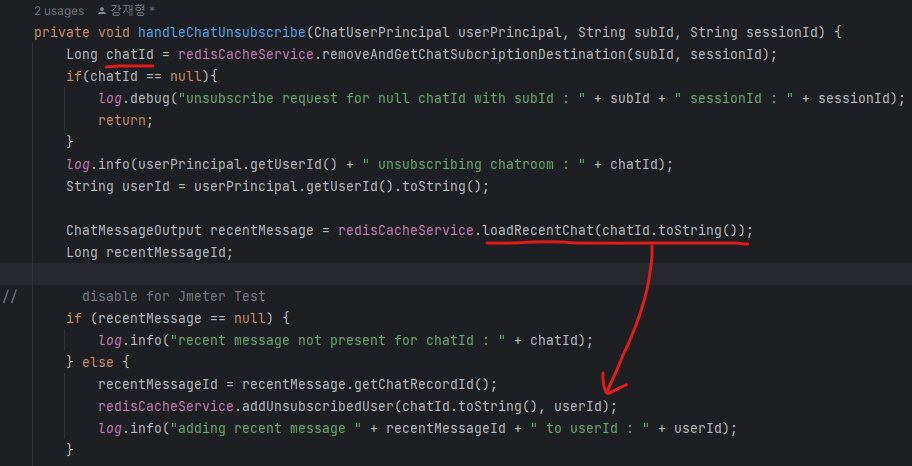
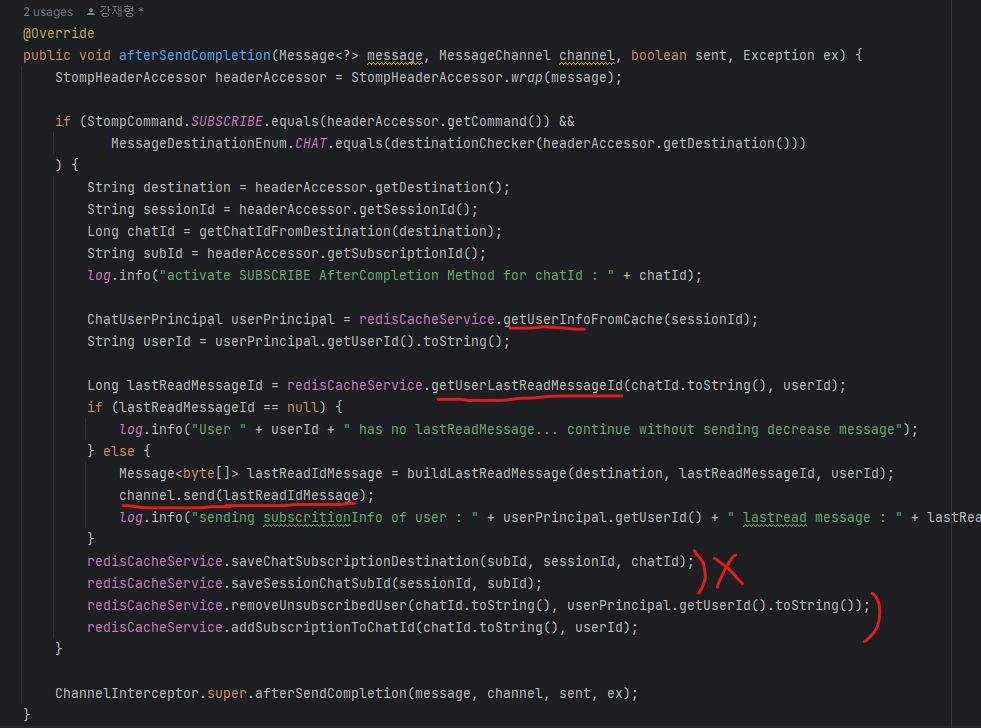
STOMP handler에서 unsubscribe를 처리해주는 메소드
ChannelInterceptor에서 command가 UNSUBSCRIBE일 경우와, DISCONNECT일 때 unsubscribe를 처리해주는 메소드
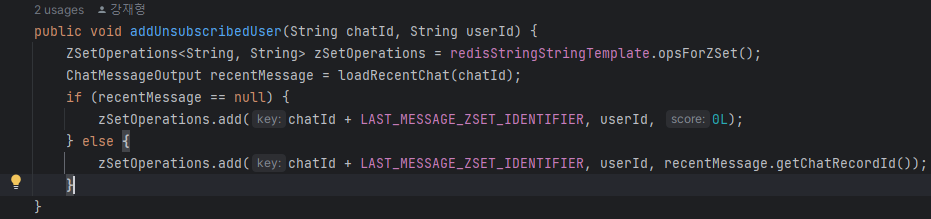
- sessionId와 subId를 통해 어느 채팅방에 구독되어있는지 확인한 후, Inactive(Unsubscribed) 유저의 lastMessage를 저장하는 메소드
- chatId와 lastMessage를 확인한 후, 실제 저장하는 addUnsubscribeUser 메소드를 호출한다
- 지금 보니 lastMessageId를 구하는데, 파라미터로 넘기지 않고 addUnsubscribeUser 메소드 내에서 lastMessage를 한번 더 확인하게 되어있다. 리팩토링 해야할듯 ?
redis에 lastMessage를 저장하는 메소드
-UnsubscribedUser는 {chatId}:lastMessage 의 key를 가지는 sorted set에 저장된다. 채팅방별로 recentchat 50개까지를 redis에 저장하고 있으므로 recentChat이 없으면 lastReadMessage를 0L로 설정 (유저가 채팅방에 가입할 경우 참여 메시지가 저장되므로 사실상 일어날 일은 없긴 하다)
- UnsubscribedUser(lastMessage 저장한 부분)에서 유저 삭제 (이제 active 유저이므로)
- SubscriptionChatId set에 유저Id 저장 (active user count)
messageId를 받아서 읽은사람 count
3.결과물 & 정리
테스트 결과
여러가지로 테스트 해본 결과 count는 정확하게 계산이 되고, 유저의 변동에도 대처할 수 있었다. (참가, 탈퇴시에 redis에
inactive 유저 관리를 해주어야 함)
구현 전에 생각했던 것과는 다르게 예상하지 못한 변수들이 많아 오래걸렸고, 코드도 마음에 들지 않게 됐다.
1. unsubscribe시에 lastMessage를 저장하면 될 것이라고 생각했는데, 실제로는 유저가 채팅창을 닫아서 unsubscribe 한 뒤에 브라우저를 종료하는 것이 아니라 그냥 채팅 중에 브라우저를 종료할 수 있다. 따라서 DISCONNECT 메시지를 받으면 유저가 subscribe중인 채팅방이 있는지 확인을 해서 서버에서 unsubscribe를 처리해주어야 한다.
DISCONNECT시에 유저의 subscription을 확인해서 unsubscribe처리를 하고 lastMessage를 저장하려면, SessionId를 통해 유저가 구독중인 채팅방을 알아야한다. (DISCONNECT시에 알 수 있는 것은 sessionId밖에 없음)
==> sessionId의 sub-Id, destination은 STOMP 내부에서 <Map, <Map, String>>의 형태로 관리되는데, 여기에 접근할 방법을 찾지 못해서 redis에 내가 별도로 저장해주어야 했다. 따라서 유저가 connect, disconnect할 때마다 redis에 삽입,삭제 등이 일어나게 되는데, 코드도 지저분해지고 중간에 프로세스가 꼬일 가능성 ↑, redis 병목현상 가능성도 ↑ 되었다. 성능 테스트 이후에 코드를 변경할 필요성이 있음
2. 메시지별 readCount를 계산할 때 메시지 개수만큼 redis에 요청이 가는 것이 별로인 것 같다. 원하는 범위의 zrange를 가져와서 내부적으로 계산하고싶은데, 추후에 리팩토링 하는 것으로 하고 일단은 메시지별로 redis에서 count를 계산해오는 방식으로 구현했다. 메시지들의 readCount를 계산하는 도중에 구독정보가 바뀌게 되면 같은 시점의 readCount를 계산한 것이 아니므로 오차가 발생하게 됨. (수정 대상, 어렵지 않게 할 수 있을듯)
3. Dynamic Programming의 개념으로 메시지별 readCount를 계산할 때 readCount가 변경되는 시점 (정렬된 Score가 distinct한 값을 가질 때) 에서만 이전 메시지의 readCount를 활용해 계산을 하려고 생각했으나, redis sortedset을 distinct score 별로 조회할 방법이 없다..
==> 어떤 방법으로 저장해야 더 효율적일지 고민 필요할 것 같다. -> 테스트 이후 고민해보기로 함
우리 서비스의 요구사항은 여러 개의 단체방이 있어 해당 채팅방에 구독할 수 있어야 했기 때문에, 구독 endpoint별로 메시지가 구분되는 것을 실험하기 위해 레퍼런스에서 주어진 view를 조금 수정해 연습해보았다.
구현 당시에 정리를 안해서 캡쳐가 안남아있음 ㅠㅠ
WebSocketMessageBrokerConfigurer를 구현해 WebSocket 연결 endpoint와, MessageBroker를 설정해주었다.
2. 채팅 서비스 구현
당시엔 controller에 내용이 없었다.
@MessageMapping은 해당 destination으로 들어오는 message를 잡아온다.
메시지를 받아서 다시 해당 채널에 발송할 때, 우리는 JWT 토큰을 Spring security filter에서 검증하는 방식을 사용하고 있었기 때문에 spring security를 타고오지 않는 STOMP 메시지의 유저 정보를 알 수 없었다. 이를 해결하기 위해 두 가지 방식을 생각했다.
1. JWT 토큰의 claim에 닉네임, 프로필URL을 세팅해두고, 모든 메시지의 헤더에 JWT 토큰을 담아서 요청하면, 이를 decode하여 메시지에 담아 전달
2. sessionId에 유저정보를 묶어서 저장
결국 나중에는 이런저런 이유로 2번과 같이 구현하게 되었지만, 이 때 당시에는 "session 정보를 관리하게 되면 JWT 토큰의 stateless 하다는 장점이 없어지는 것 아닌가?" 라고 생각하여 1번과 같이 구현하였다.
메시지 헤더에 JWT 토큰을 포함하여 이를 통해 id, nickname, profileURL을 얻고, 이를 response에 담아 전송하는 방식이다. 메시지 헤더와 sessionId, destination은 stompHeaderAccessor를 통해 stompHeader에 접근하여 얻을 수 있다.
2번의 구현도 시도는 해보았는데, webSocket handshakeInterceptor를 구현하여 handshake시에 JWT를 검증하고, 이를 sessionId에 저장하는 방식을 생각했으나, 프론트측에서 sockJS를 사용하기로 결정하여서 이는 불가능하게 되었다(sockJS 라이브러리 사용 시 보안상의 이슈로 websocket 연결 요청에 native header를 포함할 수 없다고 한다) https://github.com/sockjs/sockjs-client/issues/196
4. 인증 방법을 결정한 후에도, STOMP 프로토콜에 대한 기본적 지식(메시지의 구성, COMMAND, 헤더에 뭐가있는지, destination과 sessionId의 존재와 어떻게 접근하는지)이 없어서 매 순간이 의문이었다.
5. 개발환경을 잘 만들자 : 구현 초반에는 프론트 코드를 clone해서 내 로컬에 띄울 생각을 안했다 (node 패키지 설치 등 안해본 것에 대한 두려움). 따라서 테스트를 해 보려면 내 code에 로그를 찍어두고, push / merge 하고, 빌드와 배포를 기다린 뒤에 프론트 개발 서버로 접속해서 요청을 날려봐야 했다. 이런 식으로 하니까 불필요한 commit도 많이 쌓일 뿐더러, 작업 속도도 느리고 경험적으로 굉장히 불쾌했다. 금방 구현할 줄 알고 개발환경에 신경을 쓰지 않았는데, 초기에 환경을 세팅하고 작업했으면 시간과 에너지를 많이 아낄 수 있었을 것 같다.
참고사항 : ChannelInterceptor에서 JWT를 검증해서 메시지 헤더에 달아줘도 될텐데, controller에서 한 이유
ChannelInterceptor의 presend 메소드는 STOMP 메시지가 channel에 발행되면 거쳐가는 메소드다. 모든 메시지를 intercept할 수 있으며, header를 확인하여 어떤 COMMAND인지 확인하고, 적절한 처리를 해줄 수 있다. 따라서 controller에서 JWT decode를 하는 것 보다는 presend에서 메시지를 가로채서 유저 정보를 검증하고, 메시지 헤더에 달아주면 되는 것 아닌가? 라고 생각했다. 하지만,,,, presend에서 stomp header를 set해주더라도, 막상 메시지를 처리하는 controller에 가면 헤더 정보가 감쪽같이 사라지는 것을 확인했다. 공식 문서 등 자료를 찾아봐도 이에 관한 내용은 없었고, stackoverflow에 올린 질문에서도 답변을 구하지 못했다. 아시는 분 있으면 댓글부탁드립니다...
현재 프론트엔드, 백엔드 팀원들과 함께 SPrint라는 게시판 형식의 스터디, 프로젝트 구인 서비스를 미니프로젝트로 진행하고 있다. https://github.com/mottoslo/SPrint-Server 처음 해보는 협업이기 때문에 기획, 설계부터 시작해서 배포까지 처음 겪는 자잘한 문제들이 많아 재밌게 하고있다. 그런 부분들에 대해서는 회고 글로 따로 정리하도록 하고, 이 글에는 내가 구현을 맡은 부분에서 배운 점을 정리하려고 한다.
나는 가장 로직이 많을 것이라 예상되는 SprintService 부분의 api를 담당하였다.
스코프가 크지 않아 API 기능 짜는 것은 어렵지 않았는데, 기존에 해봤던 간단한 게시판 CRUD보다는 다룰 부분이 조금 더 많아져서 DB를 어떻게 구성할 것인지에 대한 고민 후에 시작했다.
우리 프로젝트에서는 게시글을 하나의 Sprint라고 부르기로 했다.
예시
하나의 Sprint를 보여줄 때는 게시글과 타입(스터디,프로젝트), 좋아요 개수, 모집 포지션을 보여줘야한다.
그런데, 모집 글을 작성할 때 포집 포지션의 이름과 개수, 제한인원을 유저가 자유롭게 설정할 수 있도록 기획하다 보니 Sprint entity에서 모집 필드에 대한 값을 고정적으로 가지고 있을 수 없게 되었다.
따라서, Sprint의 id와 게시글, content 등 고정적으로 들어오는 필드들은 Sprint entity에, 유동적으로 변할 수 있는 필드들은 SprintFieldEntry에 저장하자는 결론에 이르렀다.
설계는 잘 한 것 같은데, 연관관계에 대한 고민이 있었다. 기존 게시판을 만들 때 댓글에 @OneToMany연관관계를 사용해 보았는데, 지연로딩을 사용하면 글을 여러 개 조회할 시 getComment시마다 쿼리가 추가로 나가게 되었고, 즉시로딩을 사용할 시 Comment가 필요하지 않을 때에도 Comment를 가져오게 되어 좋은 설계라고 생각이 들지 않았다.
지연로딩으로 설정 해 두고, 필요할 시만 fetchjoin을 사용하면 된다는 해결책은 검색을 통해 알았으나, "fetchjoin을 사용할거면 어차피 쿼리를 작성한다는 것인데, 그러면 연관관계를 굳이 설정해주지 않아도 쿼리를 통해 해결할 수 있다" 라고 생각했었다. 따라서, 이번 프로젝트에는 FieldEntry가 단방향 @ManyToOne으로 Sprint를 바라보게 한 뒤, Sprint를 조회할 때 FieldEntry를 sprintId로 조회해 필드들을 가져오고, 서비스 로직으로 이들을 묶어주는 방식으로 구현을 하였다.
구현은 금방 하였는데, 막상 이런식으로 구현하니 코드의 가독성도 떨어지고 불필요한 작업이 많이 필요했다.
getAllSprint()나 getMySprint() 등 여러개의 sprint를 반환해야 하는 경우, 필요한 Sprint와 SprintField를 모두 가져온 후, SprintFieldList를 보면서 Sprint 별로 나눠 매핑해준 뒤, 이를 다시 responseDto로 변환하여 리스트에 담아야하는 번거로움이 있었다. 불필요한 내부 메서드가 많아지고, 이름을 아무리 상세하게 적어도 나만 알 수 있는 메서드가 되는 것 같았다.
만약 Sprint가 @OneToMany로 Entry를 가지고 있었다면, fetchjoin으로 필요한 정보를 가져옴과 동시에 Sprint객체에 Fields가 세팅되기 때문에 피할 수 있는 번거로움이라는 생각이 들었다. 쿼리를 어차피 작성해야 한다면, 더구나 Sprint와 Field같이 함께 사용될 가능성이 매우 높다면, 연관관계를 맺어주고 fetchjoin을 활용한 쿼리를 작성하여 사용하는게 훨씬 효율적이고, 가독성도 향상될 것 같다고 생각했다.
*@Query에서 fetchjoin은 join으로 가져온 객체 세팅이 필요할 때, join은 join한 테이블의 조건으로 검색만 하고 해당 컬럼들을 가져올 필요는 없을 때 사용한다.
추가로, @OneToMany를 지양하라는 의견이 많은 이유는 단방향 @OneToMany를 사용 시 외래키의 주인이 아닌 쪽에서 변경이 일어나 추가적인 update문이 나가기 때문인 것으로 보인다. 내가 @OneToMany에 대해 막연하게 안좋다고 생각한 이유(즉시로딩, 지연로딩에 관해 고민해야하는 번거로움)로 지양해야 하는 것은 아닌 것 같았다.
따라서 Sprint와 FieldEntry에 연관관계를 맺어주고, fetchjoin 쿼리를 사용하여 코드를 리팩토링 하기로 결정했다.
약간의 삽질이 있었지만, 연관관계에 대한 막연한 거부감을 덜어낼 수 있는 계기가 되었던 것 같아 감사하다.
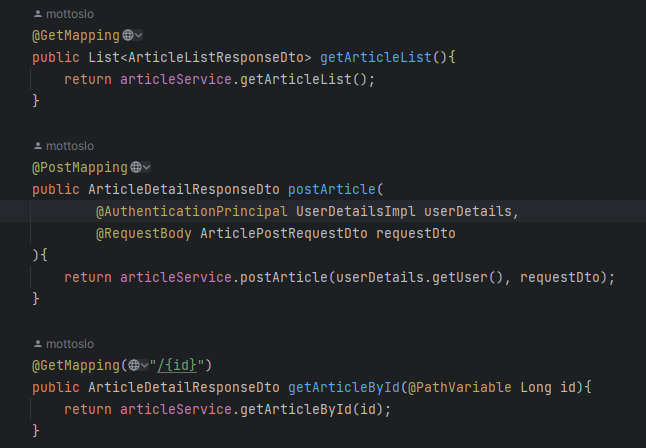
둘을 구분짓기 위해 ResponseDto를 ListResponseDto // DetailResponseDto로 나누어 받게 함
Service
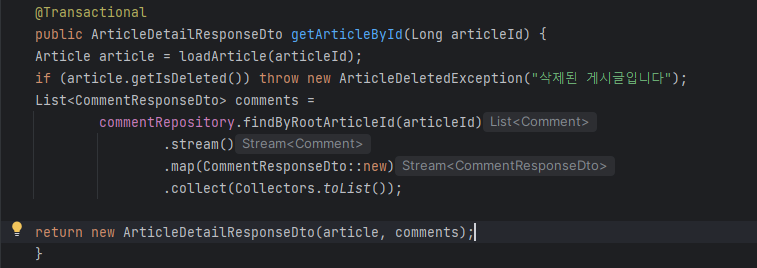
Controller에 맞게 구현했다. Article 조회 시 Comment를 어떻게 가져올지 아직 정하지 못했기 때문에, ArticleDetailResponseDto 작성을 보류했다. Comment에 대댓글 기능을 추가할 생각이기 때문에, 게시글에 달린 댓글을 모두 긁어와서 Article에 List로 나갈 댓글 목록을 만들어줄 생각이다. 자세한건 Comment에서
*추가 : 게시글 삭제 요청에 대해 DB에서 삭제하는 것이 아닌, Article의 isDeleted 필드를 true로 만들어주는 방식으로 하기로 했다. 따라서 게시글 긁어오는 부분을 findAllByIsDeletedFalse()로 대체하였다
게시글 상세조회 요청에 대해 가져온 게시글이 isDeleted면 ArticleDeletedException을 throw하도록 바꾸었다.
<Comment 관련 기능>
Comment 기능에 대댓글 기능을 구현할 생각이다. 구현 방법으로는 여러가지가 있을 것이다.
1. Comment 내부에 Comment필드를 가져 연관관계 맺어주기
- Comment와 Comment의 연관관계를 정의할 수가 없다. (댓글인지, 대댓글인지에 따라 관계가 달라지니까)
2. 대댓글 entity를 만들어 관리
- 대댓글이 한 depth로만 달리면 괜찮은 방법일 수 있지만, 대댓글에도 대댓글을 달 수 있는 경우 계속 Entity를 만들어주어야 하기 때문에 좋지 않다고 생각함
3. Comment에 commentType 필드를 가져서 게시글에 단 댓글인지 Comment에 단 댓글인지 분류
- Article을 조회했을 때 commentType이 ArticleComment인 댓글을 가져오고, 해당 댓글들에 대해서 commentType이 CommentComment 인 애들을 전부 조회한 뒤 Id를 비교해야 하기 때문에 쿼리가 불필요하게 많이 나가게 될 것 같다.
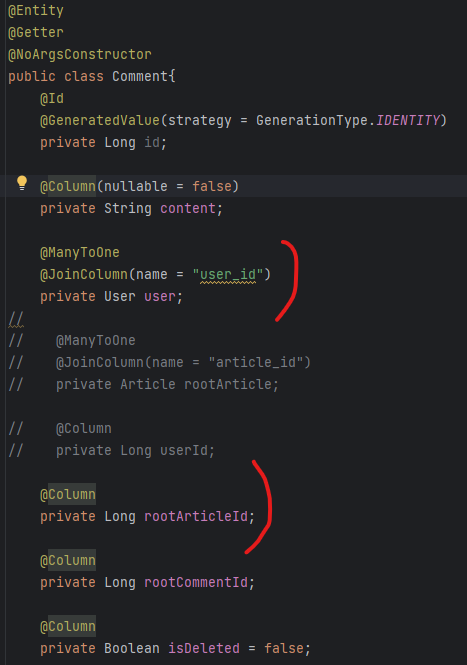
4. 댓글과 대댓글을 구분짓지 않고 Comment 엔티티로 관리하며, nullable한 rootComment 필드를 가지게 한다.
Article 조회 시, 해당 Article에 달린 댓글 전부를 긁어온다. CommentBuilder 메소드를 하나 만들어 Comment를 구분하 고, 댓글이 대댓글을 포함하도록 하는 로직을 구현한다.
==> 4번은 추가적인 로직을 구현해야 해서 복잡할 것 같지만, 이렇게 하는게 맞는 방법 같아서 이렇게 하기로 함.
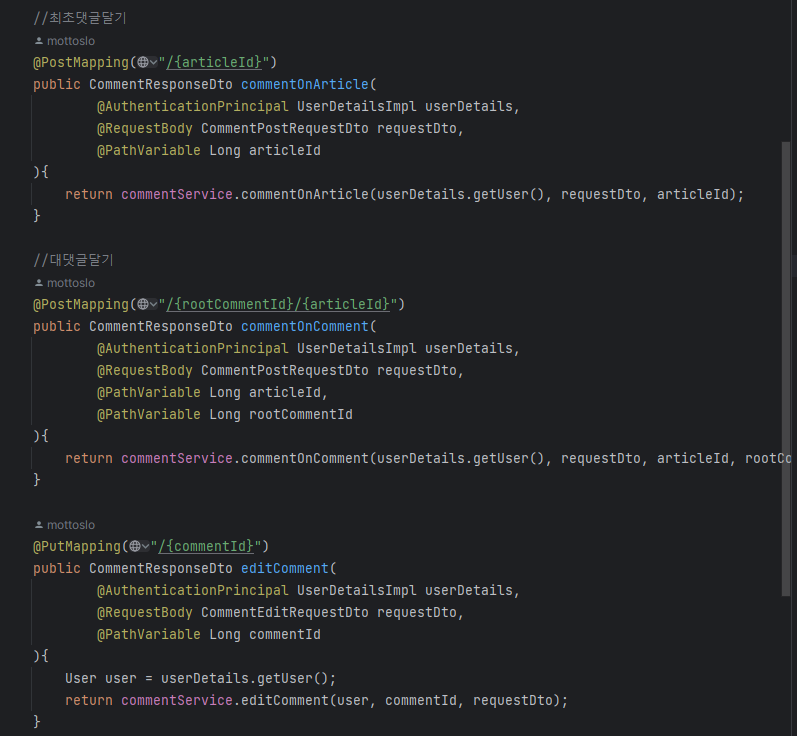
일단, 댓글과 대댓글의 관계를 정리해주는 로직을 제외하고, Comment 등록/삭제/수정 기능을 구현하려고 한다.
또한, 댓글 삭제 시에도 대댓글은 유지하기 위해 댓글 삭제 요청에 대해 DB에서 댓글을 삭제하는 것이 아닌, isDeleted flag를 true로 바꿔주는 방식으로 구현하려고 한다. 이에 따라 CommentResponseDto의 생성자에는 isDeleted를 확인하고, 삭제된 댓글일 시에는 Dto의 content를 "삭제된 댓글"로 바꿔주어야한다.
추가로, 테스트를 위해 Article에서 Comment를 조회하는 부분을 일단 모든 Comment를 조회하도록 구현하려고 한다.
(Article상세조회부분)
Article상세조회
(CommentController)
user의 고유ID만 넘겨주면 좋겠지만, 서비스에서 User의 권한을 확인하고 관리자일 시 요청을 처리해주도록 API가 설계되어있기 때문에 User객체 자체를 넘긴다
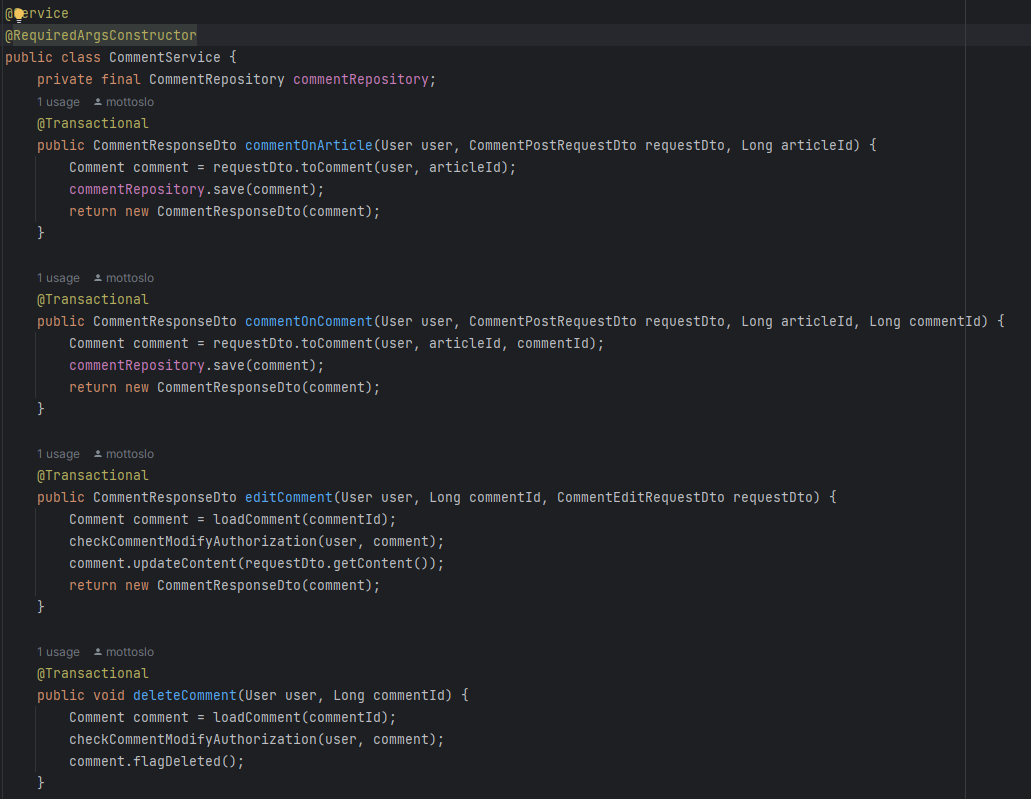
(CommentService)
delete요청에 대해 DB에서 삭제하는 것이 아니라, comment 엔티티의 isDeleted 값을 true로 바꾸는 메서드를 구현했다.
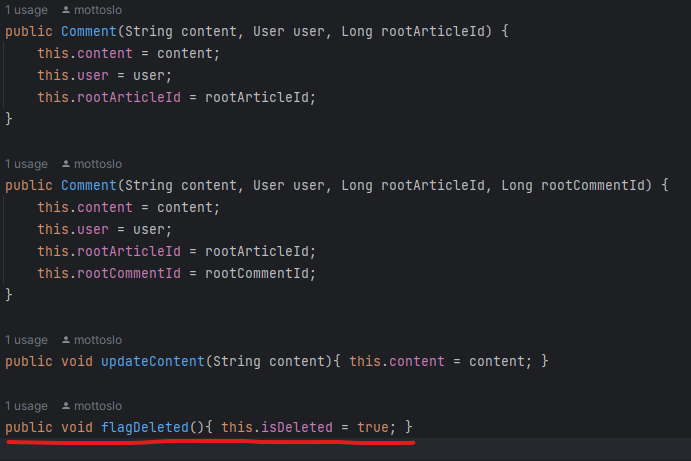
Comment 엔티티의 생성자와 메서드
Comment의 생성자는 Article에 단 Comment인 경우와 대댓글의 경우를 나누어서 오버로딩 해주었다.
기존에는 Comment의 생성자에 CommentRequestDto를 받도록 하였는데, CommentRequest가 바뀔 가능성이 있다는 점을 생각해보면 이에 따라 도메인인 Comment 엔티티의 생성자가 바뀌어야 하는것은 좋지 않다고 생각했다.(의존성문제)
따라서 생성자로 필드값을 받게 한 뒤,
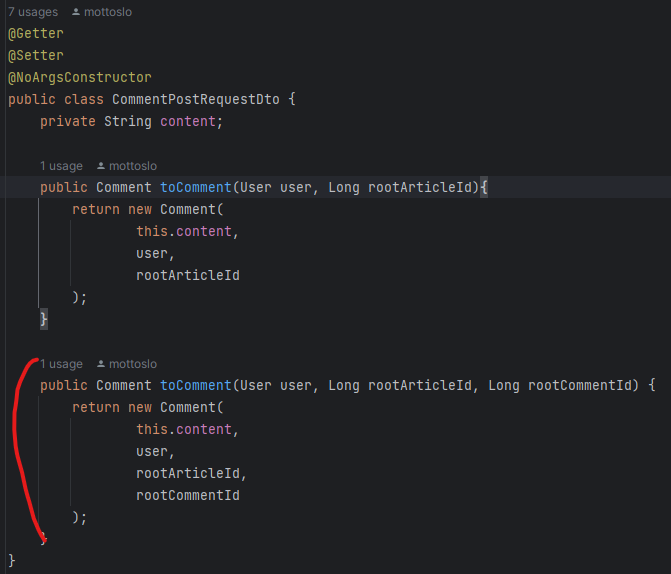
Dto의 Comment 생성 메서드
requestDto에서 Comment객체를 만드는 메서드를 통해 Comment를 생성하도록 하였다.
이렇게 하면 Comment요청을 받는 방식이 바뀐다 하더라도 도메인인 Comment 엔티티를 바꾸는 것이 아니라 Dto의 메서드만 바꾸면 된다.
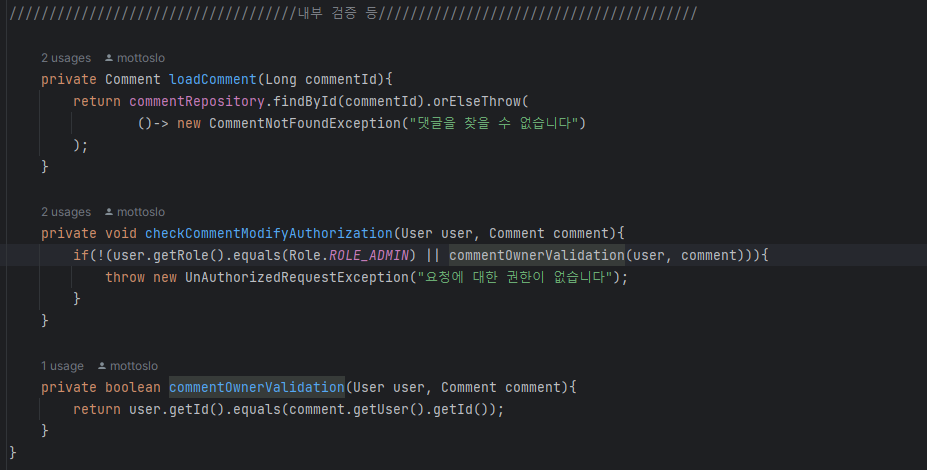
(CommentService 내부 메서드 리팩토링)
Comment를 Optional로 불러오는 부분과, 해당 코멘트 삭제/수정 요청에 대해 작성자가 맞는지 혹은 관리자권한이 있는지를 검증하는 부분은 중복되기 때문에 따로 빼주었다.
<엔티티 연관관계 변경>
기존에는 한 객체에서 다른 객체를 조회할 일이 있으면 연관이 있다고 생각하여 @OneToMany나 @ManyToOne을 사용하여 연관관계를 맺었다. 전체적인 설계를 먼저 하고, 그에 맞게 연관관계를 맺어주는 것이 더 좋은 것 같다.
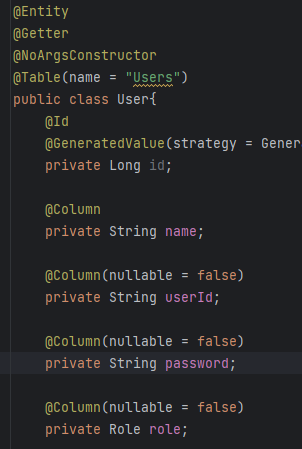
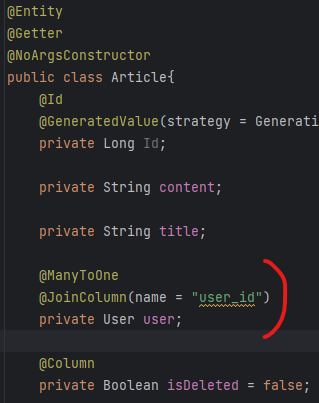
1. User와 Article의 관계 : 단방향 @ManyToOne
- 기존에는 User가 @OneToMany로 Article을, Article이 @ManyToOne으로 User를 바로보게 하였다.
이렇게 했을 때 장점은 user.getArticles로 작성 글 목록을 한번에 가져올 수 있다는 것이 있다.
회원 Entity가 모든 요청에 조회되는데 비해 비중이 굉장히 낮은 이점일 뿐더러, 이런식으로 설정 했을 때 fetch되어야하 는 시점이 언제인지, Article의 연관관계는 어떻게 되는지 등 생각할 것이 많아진다. 따라서 이번엔
Article이 User를 단방향 @ManyToOne으로 바라보는 관계로 설정하였다. 게시글이 조회될 땐 거의 무조건 작성자를 알 아야 하기 때문이다.
*Article의 User필드는 user_id가 아닌 User 객체로 한 이유는 Article을 조회할 때 username(작성자 닉네임)을 알아야하는데, Article의 필드에 가지고 있는 외래키는 고유id이다. 따라서 Article을 가지고 올 때 User객체를 같이 가져와야 작성자명을 찾기 위한 추가 쿼리가 나가지 않게 된다.
2. User와 Comment의 관계 : 단방향 @ManyToOne
- 1과 마찬가지의 이유로 Comment가 @ManyToOne으로 User를 바라보게 하였다.
3. Comment와 Article의 관계 : 연관관계없이 필드값으로 id 가지고있기
- Article의 경우 전체 글 목록을 보여줄 때는 Comment를 알 필요가 없다. 따라서 게시글 상세보기 시에만 Comment 엔티티에서 Article의 id로 검색하여 댓글을 가져오면 된다.
Comment에서 Article에 대해 알아야할 정보는 Article의 고유번호밖에 없다. Comment를 통해서 해당 댓글이 달린 Article의 내용이나 작성자를 조회할 일이 없기 때문이다. 따라서 따로 연관관계를 맺어주지 않고, Article의 고유id를 하나의 필드article_id로 가지게 하였다. Article에서 해당 글의 Comment를 가지고 올 때는 findby article_id로 쿼리를 날리면 된다.
저장할 때는 어차피 요청 쿼리스트링에서 해당 게시글의 id를 가지고 들어오기 때문에 Article 객체를 찾는 추가적인 쿼리가 나갈일이 없다.