현재 프론트엔드, 백엔드 팀원들과 함께 SPrint라는 게시판 형식의 스터디, 프로젝트 구인 서비스를 미니프로젝트로 진행하고 있다. https://github.com/mottoslo/SPrint-Server 처음 해보는 협업이기 때문에 기획, 설계부터 시작해서 배포까지 처음 겪는 자잘한 문제들이 많아 재밌게 하고있다. 그런 부분들에 대해서는 회고 글로 따로 정리하도록 하고, 이 글에는 내가 구현을 맡은 부분에서 배운 점을 정리하려고 한다.
나는 가장 로직이 많을 것이라 예상되는 SprintService 부분의 api를 담당하였다.
스코프가 크지 않아 API 기능 짜는 것은 어렵지 않았는데, 기존에 해봤던 간단한 게시판 CRUD보다는 다룰 부분이 조금 더 많아져서 DB를 어떻게 구성할 것인지에 대한 고민 후에 시작했다.
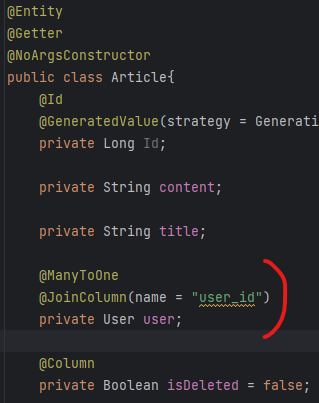
우리 프로젝트에서는 게시글을 하나의 Sprint라고 부르기로 했다.

하나의 Sprint를 보여줄 때는 게시글과 타입(스터디,프로젝트), 좋아요 개수, 모집 포지션을 보여줘야한다.
그런데, 모집 글을 작성할 때 포집 포지션의 이름과 개수, 제한인원을 유저가 자유롭게 설정할 수 있도록 기획하다 보니 Sprint entity에서 모집 필드에 대한 값을 고정적으로 가지고 있을 수 없게 되었다.
따라서, Sprint의 id와 게시글, content 등 고정적으로 들어오는 필드들은 Sprint entity에, 유동적으로 변할 수 있는 필드들은 SprintFieldEntry에 저장하자는 결론에 이르렀다.
설계는 잘 한 것 같은데, 연관관계에 대한 고민이 있었다. 기존 게시판을 만들 때 댓글에 @OneToMany연관관계를 사용해 보았는데, 지연로딩을 사용하면 글을 여러 개 조회할 시 getComment시마다 쿼리가 추가로 나가게 되었고, 즉시로딩을 사용할 시 Comment가 필요하지 않을 때에도 Comment를 가져오게 되어 좋은 설계라고 생각이 들지 않았다.
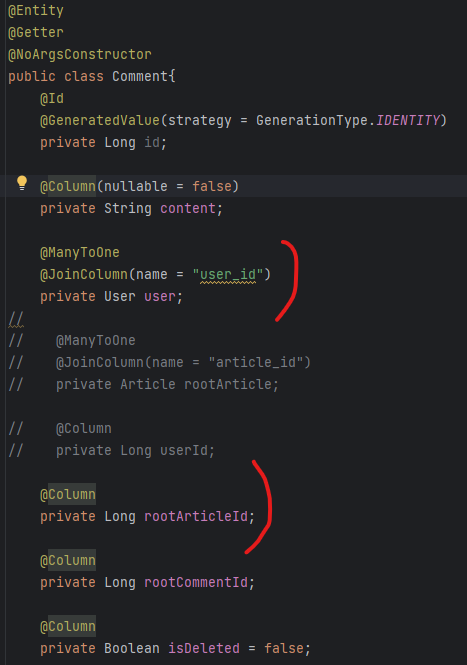
지연로딩으로 설정 해 두고, 필요할 시만 fetchjoin을 사용하면 된다는 해결책은 검색을 통해 알았으나, "fetchjoin을 사용할거면 어차피 쿼리를 작성한다는 것인데, 그러면 연관관계를 굳이 설정해주지 않아도 쿼리를 통해 해결할 수 있다" 라고 생각했었다. 따라서, 이번 프로젝트에는 FieldEntry가 단방향 @ManyToOne으로 Sprint를 바라보게 한 뒤, Sprint를 조회할 때 FieldEntry를 sprintId로 조회해 필드들을 가져오고, 서비스 로직으로 이들을 묶어주는 방식으로 구현을 하였다.
구현은 금방 하였는데, 막상 이런식으로 구현하니 코드의 가독성도 떨어지고 불필요한 작업이 많이 필요했다.
getAllSprint()나 getMySprint() 등 여러개의 sprint를 반환해야 하는 경우, 필요한 Sprint와 SprintField를 모두 가져온 후, SprintFieldList를 보면서 Sprint 별로 나눠 매핑해준 뒤, 이를 다시 responseDto로 변환하여 리스트에 담아야하는 번거로움이 있었다. 불필요한 내부 메서드가 많아지고, 이름을 아무리 상세하게 적어도 나만 알 수 있는 메서드가 되는 것 같았다.
만약 Sprint가 @OneToMany로 Entry를 가지고 있었다면, fetchjoin으로 필요한 정보를 가져옴과 동시에 Sprint객체에 Fields가 세팅되기 때문에 피할 수 있는 번거로움이라는 생각이 들었다. 쿼리를 어차피 작성해야 한다면, 더구나 Sprint와 Field같이 함께 사용될 가능성이 매우 높다면, 연관관계를 맺어주고 fetchjoin을 활용한 쿼리를 작성하여 사용하는게 훨씬 효율적이고, 가독성도 향상될 것 같다고 생각했다.
*@Query에서 fetchjoin은 join으로 가져온 객체 세팅이 필요할 때, join은 join한 테이블의 조건으로 검색만 하고 해당 컬럼들을 가져올 필요는 없을 때 사용한다.
추가로, @OneToMany를 지양하라는 의견이 많은 이유는 단방향 @OneToMany를 사용 시 외래키의 주인이 아닌 쪽에서 변경이 일어나 추가적인 update문이 나가기 때문인 것으로 보인다. 내가 @OneToMany에 대해 막연하게 안좋다고 생각한 이유(즉시로딩, 지연로딩에 관해 고민해야하는 번거로움)로 지양해야 하는 것은 아닌 것 같았다.
따라서 Sprint와 FieldEntry에 연관관계를 맺어주고, fetchjoin 쿼리를 사용하여 코드를 리팩토링 하기로 결정했다.
약간의 삽질이 있었지만, 연관관계에 대한 막연한 거부감을 덜어낼 수 있는 계기가 되었던 것 같아 감사하다.
'공부 > Spring' 카테고리의 다른 글
| CRUD 게시판 리팩토링해보기 - <2> 프로젝트 구조 만들기, Entity 생성, Exception handler (0) | 2023.04.29 |
|---|---|
| CRUD 게시판 리팩토링해보기 - <1> Spring Security, Jwt인증 적용 (0) | 2023.04.27 |
| Spring Security (0) | 2023.04.25 |
| ExceptionHandler // ResponseEntity // HTTP 상태 반환 (0) | 2023.04.23 |
| 간단한 게시판 CRUD // 로그인, 회원가입, JWT 추가 (0) | 2023.04.20 |